![]()
Hypertext; Information, Area of Uncertainty and
Hypertext
José Enrique González Cornejo
Chile-1990
") Excerpts
from Chapter IV IV NAVIGATION MAPS of "Hypertext: Its Usue in Documentary Treatment of Data" Excerpts
from Chapter IV IV NAVIGATION MAPS of "Hypertext: Its Usue in Documentary Treatment of Data"José Enrique González Cornejo Centro de Investigación y Desarrollo de la Educación Research and Development of Education, CIDE, Santiago - Chile, 1991. |
 |
|
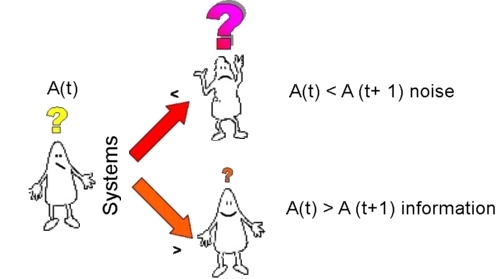
IV NAVIGATION MAPS IV.1 Information, Area of Uncertainty and Hypertext When a user interacts with the computer, the volume of information available is not only huge, but also the time ¡t takes to respond is increasingly shorter. Only recently, ¡t took the computer a certain amount of time to respond to an inquiry, allowing the user to prepare alternative questions. Today, this interaction is virtually simultaneous, replacing the gap with a direct dialogue, and changing the cognitive process. The enormous volume of information integrated and made available by a documentation centre to computer inquiries can enlarge the user's "area of uncertainty" instead of reduce ¡t. This situation can be said to produce more noise than information. Suppose we could measure the
area of uncertainty at a given moment as a user seeks information: let
A(t) represent the first me measurement, and let A(t+1) represent the
measurement of the area of uncertainty after a computer search; then we
can postulate the following alternatives: |
There are a number of potential causes for the first possibility. The documentation centre itself could be the cause, but there could also be a series of interconnected reasons for noise, e.g., it could be that the selection criteria and information filters are not correctly formulated by the user, and/ or the documentation centers does not have the right tools for organizing large volumes of information in such a way as to be able to significantly reduce the user's area of uncertainty. For this reason, there is a growing search today for interpretative software and not only knowledge. In this case, hypertext could play a crucial role as interpreter in the process of transforming an answer, which could be noise in a given context, into information, without fear of falling into "inductive reasoning," and distorting the main idea of hypertext, which is essentially to arouse interest in autonomous research, endow the user with freedom of movement, enhance creativity and integrate knowledge.
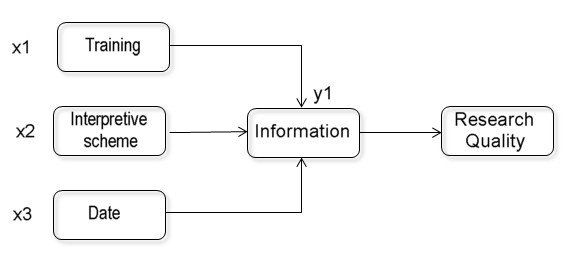
IV.2 Training and "Interpretative Schemes" User interaction with systems necessarily entails two tasks for information production centres: training users and designing information interpretation schemes. The first task is accomplished by teaching users how to formulate selection criteria and improve skills in using interactive computer programs. The second task entails elaborating "transformation functions" for changing into an analog spheres, shaped according to patterns determined by the experience of the production on centre. In other words, model the information so that it provides the user with more understanding, rapid decision-making with respect to the mass of information, and the capacity to employ the outputs.
These transformation fie1ds are developed under the concept of "expert system" and could contribute a number of possibilities for information management.
|